
怎样使用ARENA系统
表访问方式
table scan(表扫描)
对表中数据从头到尾一行一行进行扫描,判断是否满足where条件
index scan(索引扫描)
索引的必要性
索引在某些情况下可以加快对表行的访问速度,减少磁盘I/O操作,但SQL 引擎必须继续维护针对表定义的所有索引,而不管查询是否使用它们,所以需要对索引的必要性进行考虑。
通常,在以下任一情况下,请考虑在列上创建索引:
- 索引列经常被查询,并返回表中总行数的一小部分。
- 索引列上存在参照完整性约束。索引是避免全表锁定的一种方法,否则在更新父表主键、合并到父表或从父表中删除时,将需要全表锁定。
- 唯一键约束将放置在表上,并且您希望手动指定索引和所有索引选项。
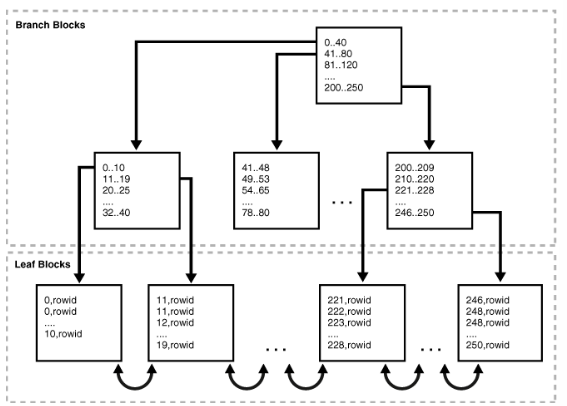
B树索引
B树索引有两种类型的块:用于搜索的分支块和存储值的叶块。
B树指数是平衡的,因为所有叶块自动保持相同的深度。索引高度是从根块到叶块所需的块数,分支级别是高度减去1。下图中索引高度为3,分支级别为2。如果数据库扫描索引以查找值,则它将在n个I/O中找到此值,其中n是B树索引的高度。
叶块包含每个索引数据值和用于查找实际行的相应rowid,每个条目按(键、rowid)排序。在叶块中,键和rowid链接到其左右同级条目。叶块本身也是双重连接的,在下图中,最左边的叶块链接到第二个叶块。
仅索引扫描(index only scan)
这与索引扫描非常相似,但数据直接来自索引,并且专门处理可见性检查,因此可以完全避免查看表数据。仅索引扫描速度更快,但并不总是可作为常规索引扫描的替代方法。
它有两个限制:
- 索引类型必须支持仅索引扫描(常见的 btree 索引类型始终支持),
- 查询必须仅投影索引中包含的列。
如果您有 SELECT * 查询,但实际上并不需要所有列,则只需更改列列表即可使用仅索引扫描。
全索引扫描
完整索引扫描中,数据库按顺序读取整个索引。如果 SQL 语句中的谓词(where子句)引用索引列,或某些未指定任何谓词的情况,则使用完整的索引扫描可以消除排序,因为数据本身就是基于索引键排序。
快速全索引扫描
快速全索引扫描是一种全索引扫描,数据库仅访问索引本身中的数据,而无需访问表,数据库并不按特定的顺序读取索引块。
当下面的条件同时满足时,快速完全索引扫描可以替代全表扫描
- 索引必须包含查询所需要的所有列
- 查询结果不会集中出现全是 NULL 的行,要想保证这一点,至少有一个索引列列符合下面的条件之一:
- NOT NULL 约束
- 应用到该列的谓词阻止 NULL 值作为结果集

哈希索引
由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引。
HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。但是,这种高效是有条件的,即只在“=”和“in”条件下高效,对于范围查询、排序及组合索引仍然效率不高。
filter方法(筛选)
django的filter方法是从数据库的取得匹配的结果,返回一个对象列表,如果记录不存在的话,它会返回[]。
Spool方法
在生产中常会遇到需要将数量比较大的表值导入到本地文本文件中. 方法有很多种,比较常用的就是spool命令:
2.sql
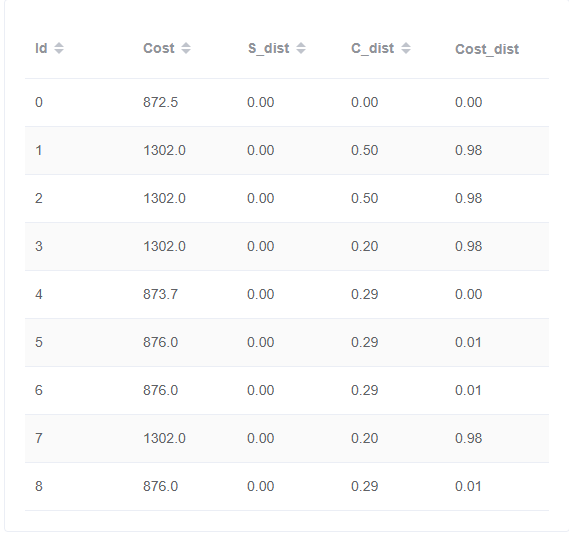
id 0
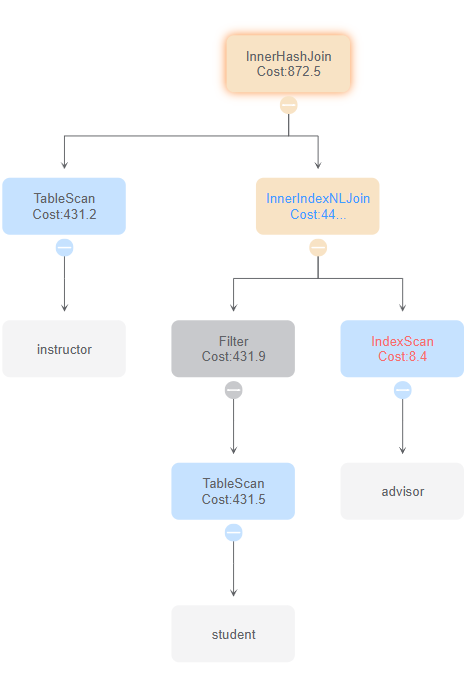
与id 4、5、6、8比较,发现连接两表的顺序会影响最终的时间花费
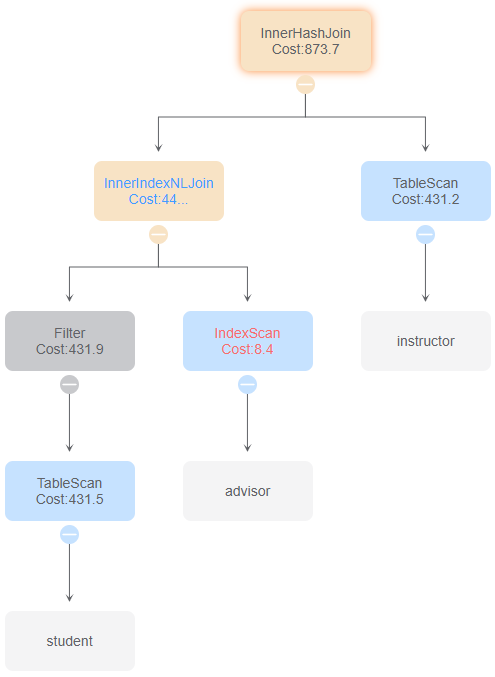
与id 1、2、3、7比较,发现恰当的使用索引扫描和索引连接可以有效地减少时间花费
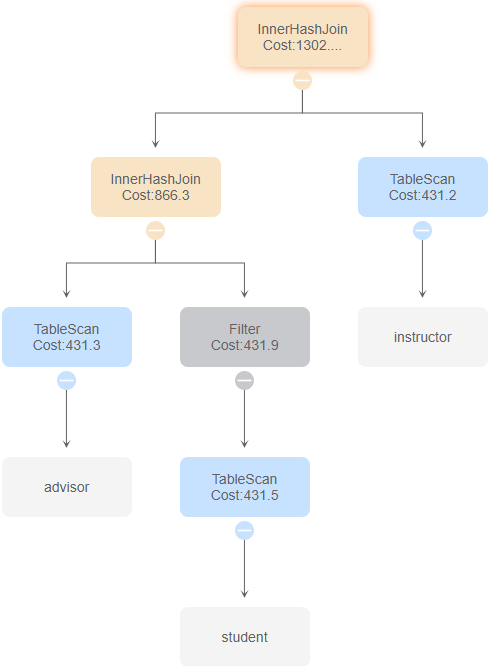
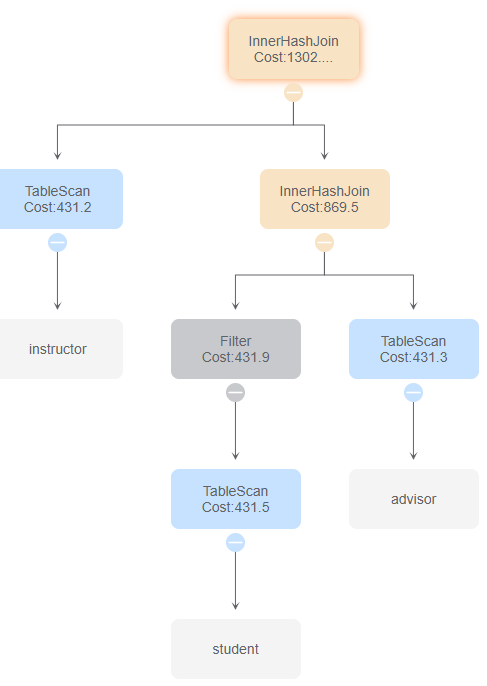
3.sql
id 0
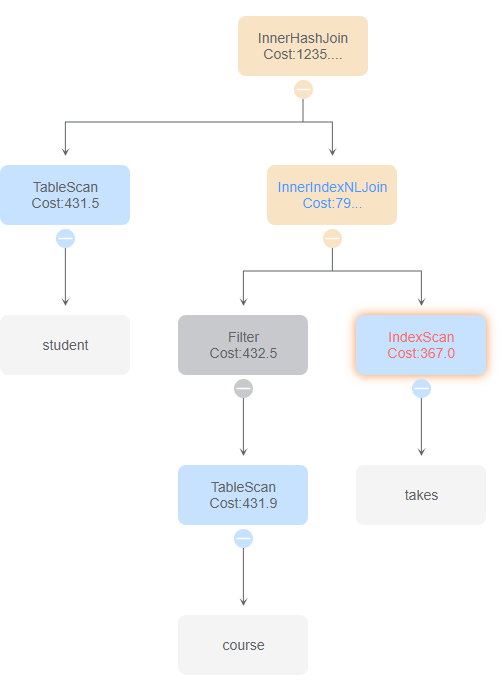
与id 5、8比较,区别在于takes表的扫描方式为IndexScan和IndexOnlyScan,时间花费影响不是很大。
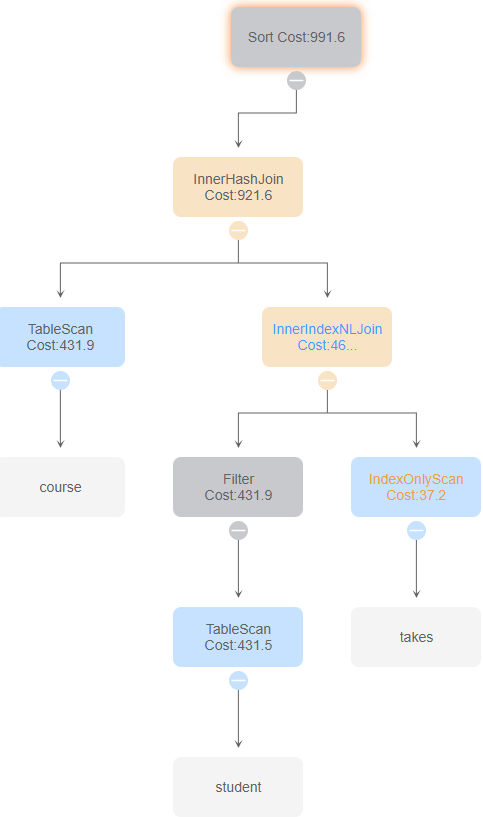
与id 4、6比较,区别为InnerHashJoin的顺序,影响最终的时间花费
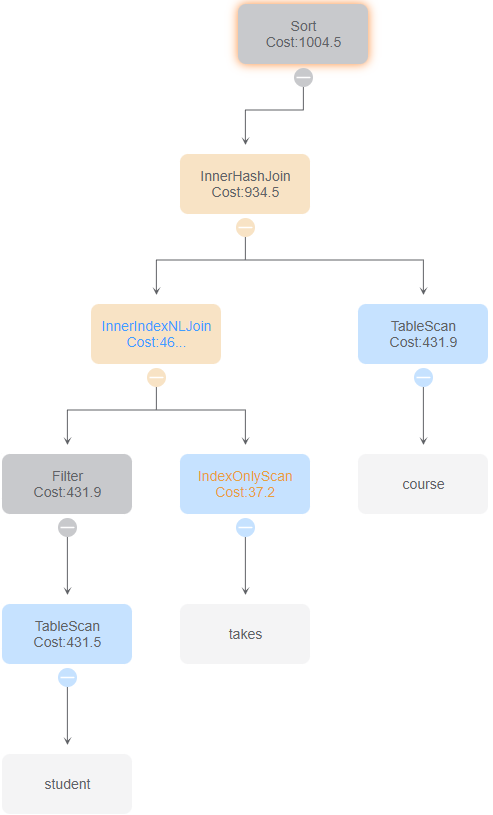
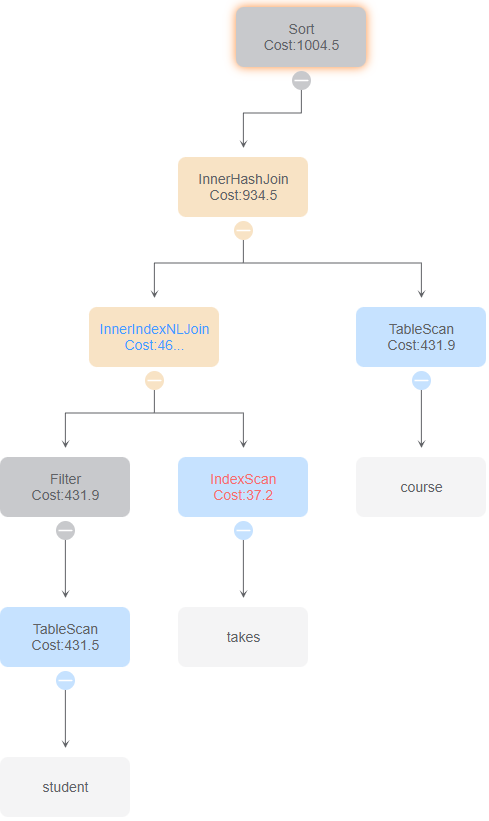
与id 2、7比较,使用索引扫描和索引链接
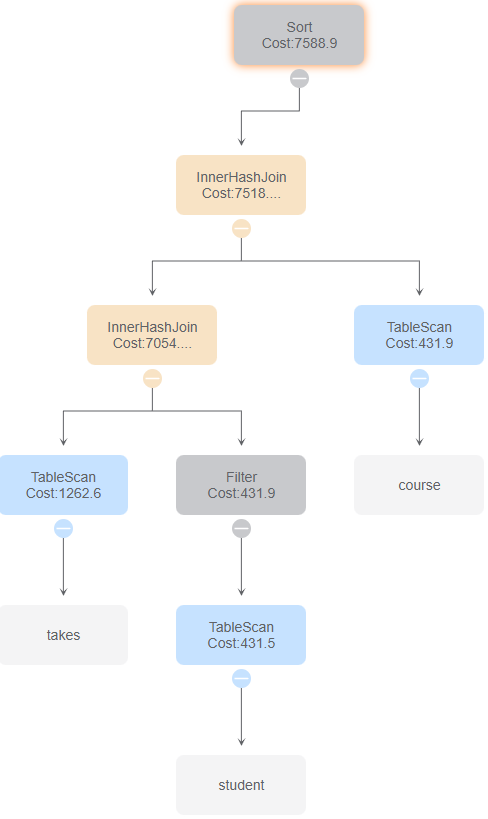
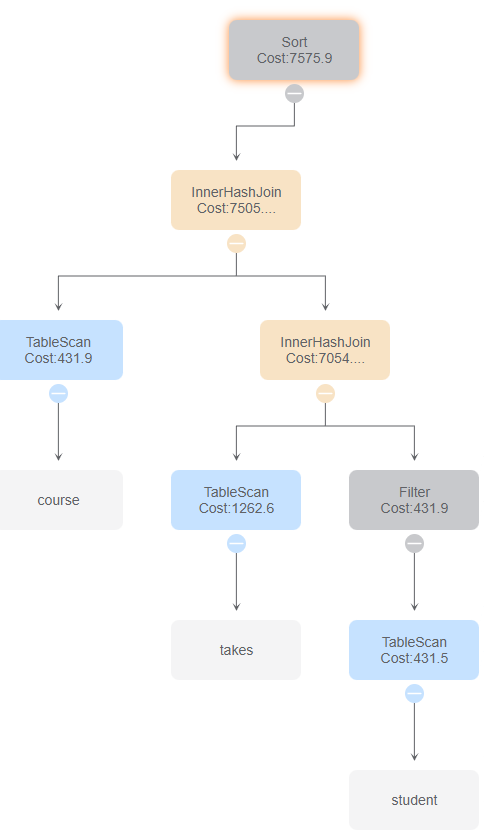
与id 1、3比较,使用了MotionGather
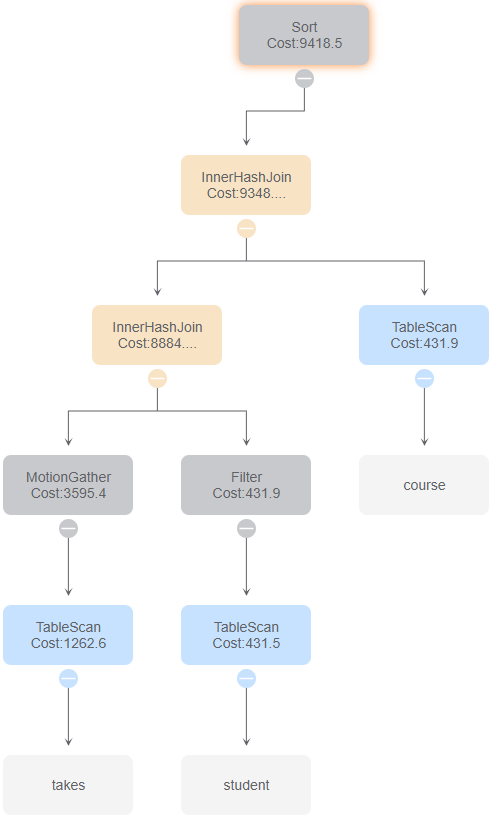
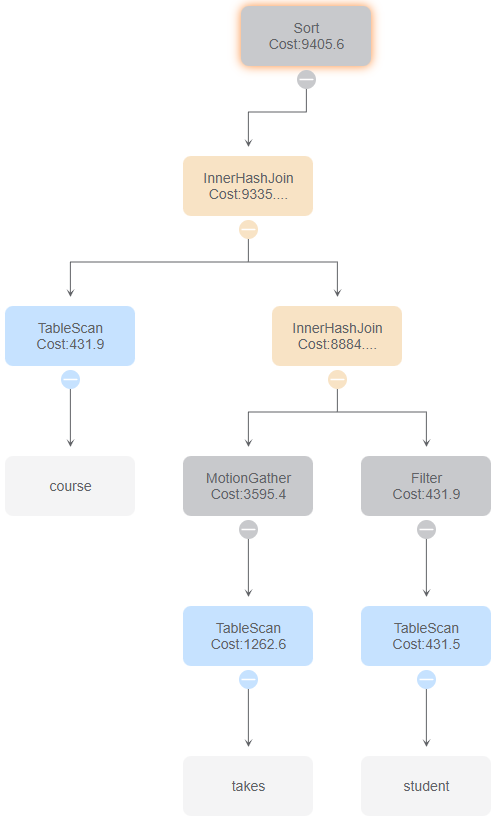
4.sql
id 0
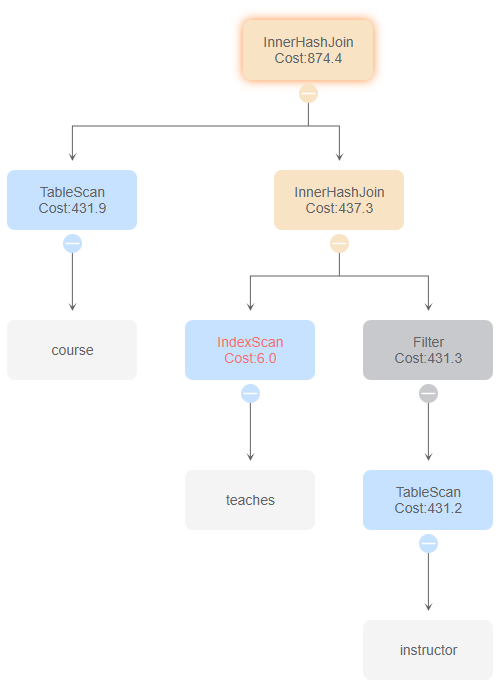
与id 8比较,使用IndexOnlyScan。
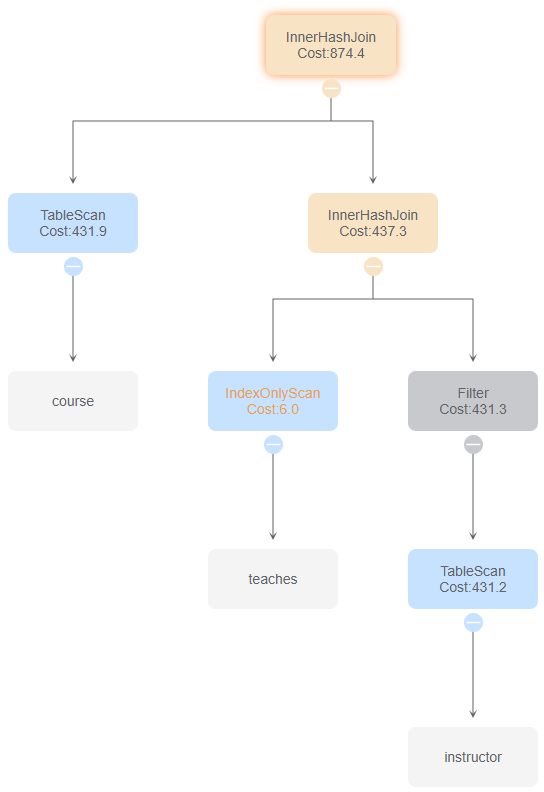
与id 4比较,通过谓词下沉,减少连接的操作量
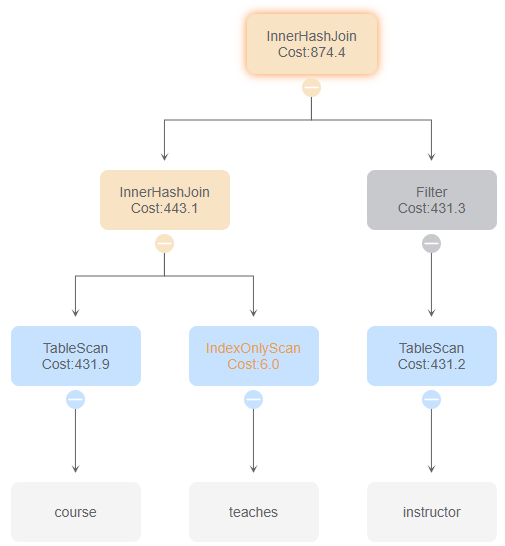
与id 6比较,改变了两次连接的顺序
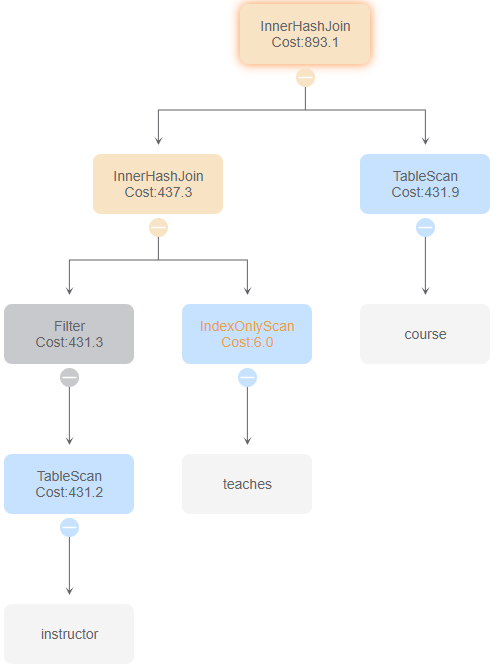
与id 5比较,没有使用索引扫描
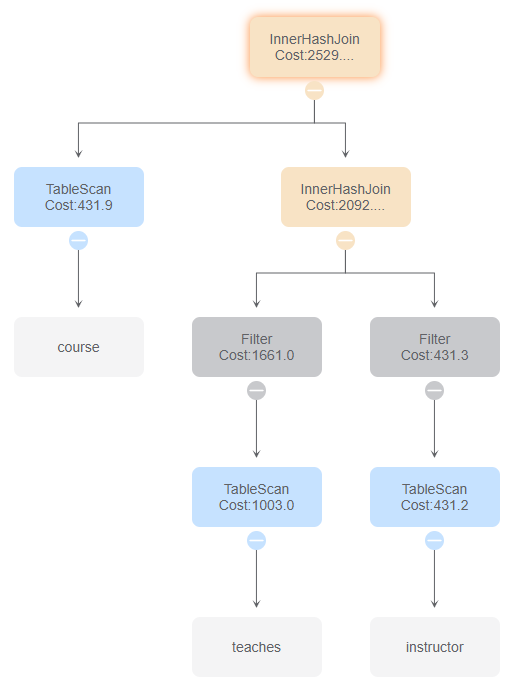
与id 2、7 比较,由于2、7使用了嵌套循环连接,使得时间花费大大提高
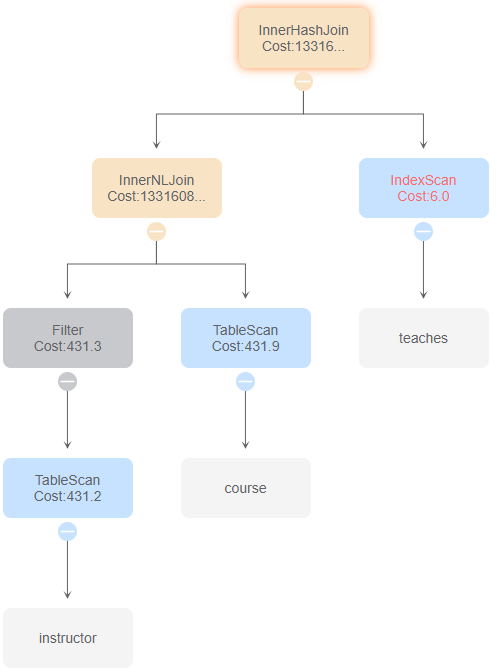
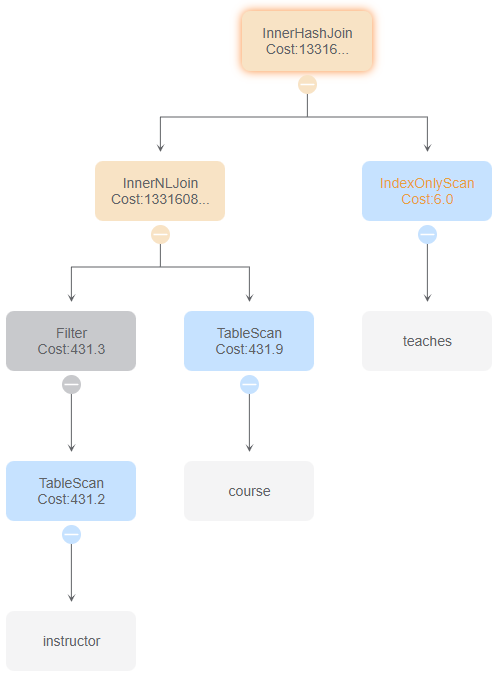
与id 3比较
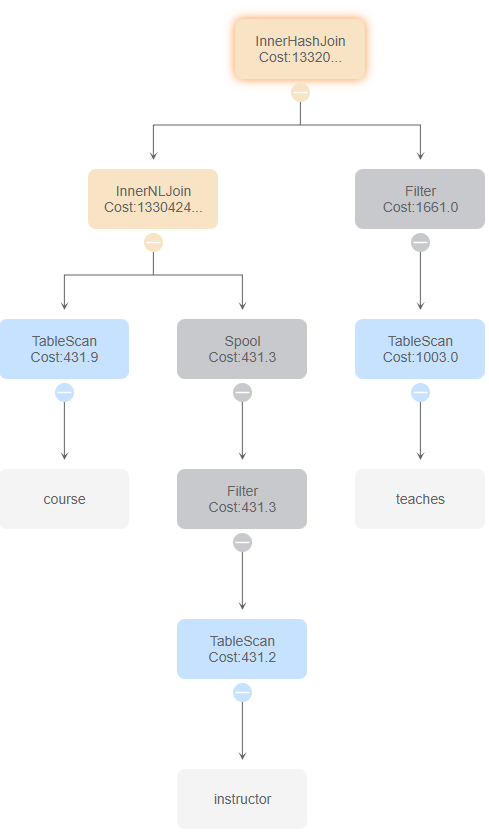
与id 1比较
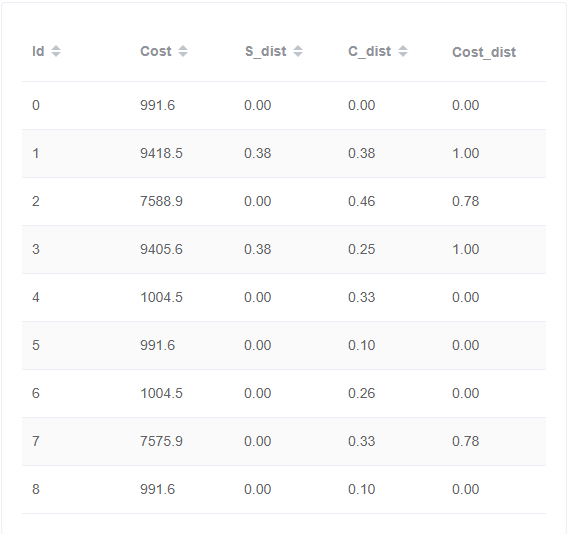
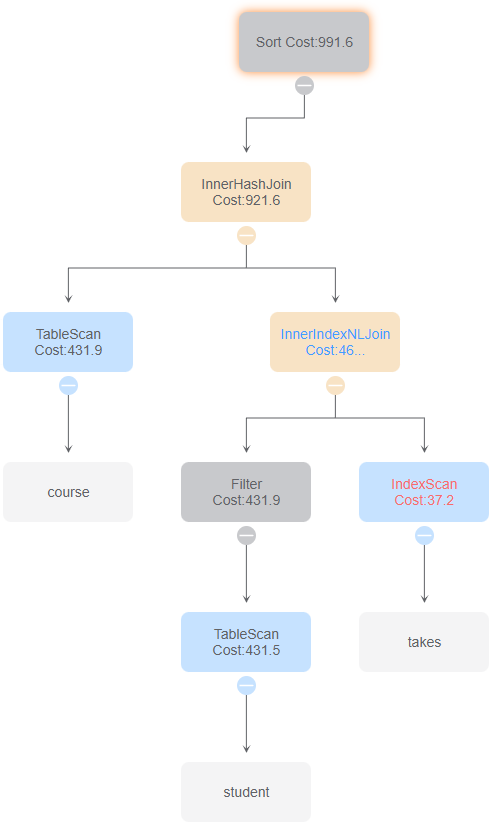
5.sql
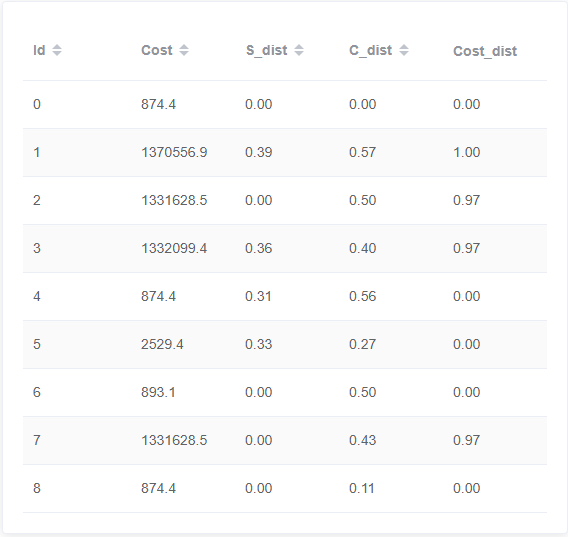
0、12、37、58、4、6
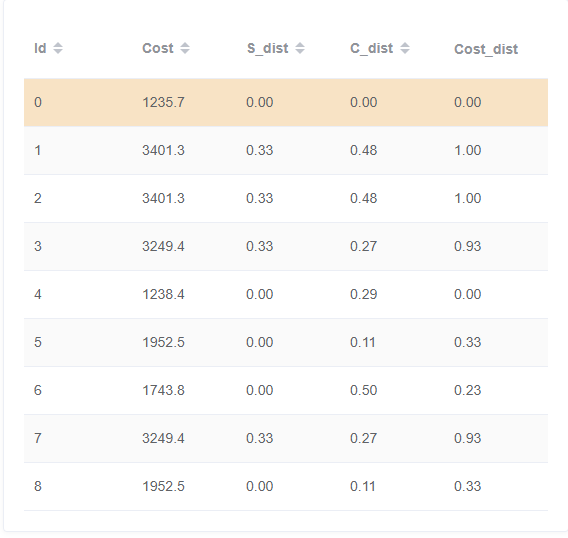
id 0
0与12对比体现索引扫描和索引连接的优点、哈希连接顺序的花费差异
0与37对比体现索引扫描和索引连接的优点
0与4对比体现哈希连接顺序的花费差异
0与58对比体现连接索引连接的优点
0与6对比体现连接索引连接的优点,哈希连接顺序的花费差异
id 12价值最大,该案例结合了id 37中索引扫描和索引连接的优点与id 4中哈希连接顺序的花费差异。id 12在takes和course表的扫描上选择了全表扫描,在对谓词进行条件筛选后进行哈希连接,而id 0对takes表采用了索引扫描,并且在对takes与course表中的course_id连接时采用了索引连接,大大加快了对表行的访问速度,从而使得时间花费大大减小。除此之外,id 1、2还在最后course_takes与student表的哈希连接中调换了两表之间的顺序,会对时间开销有一定影响
id 4价值最小,该案例体现哈希连接顺序影响的时间花费差异。而我们从其他几个案例可以发现,id 37与id 12对比,发现id 12调换了course_takes与student表的哈希连接顺序,间接体现了哈希连接顺序影响的时间花费差异;id 6与id 58对比,发现id 6调换了course与takes表之间的哈希连接顺序、student与course_takes表的哈希连接顺序,也能间接体现哈希连接顺序影响的时间花费差异。id 4例所说明的关系可由上述推算出来,故略显多余。
6.sql
0、1、2、3、4、5、6、7、8
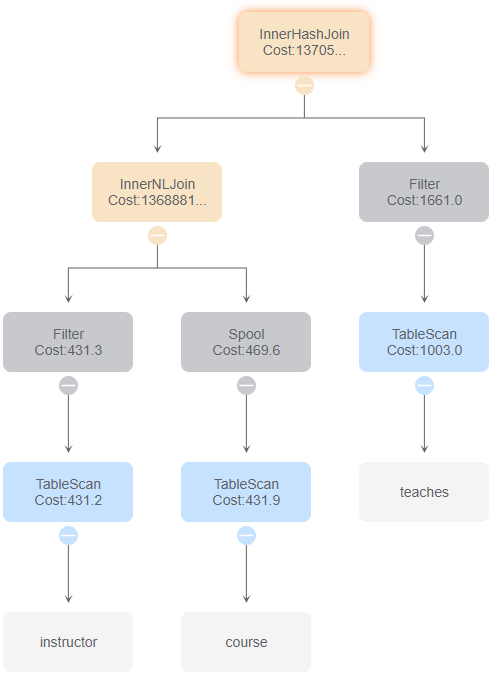
0与1对比,在id 7的基础上,id 1对course表全表扫描后得到的数据进行Spool操作,再进行嵌套循环连接
0与2对比,在id 7的基础上,id 0对teachers表的扫描中采用索引扫描,id 2对teachers表的扫描采用仅索引扫描。
0与3对比,在id 7的基础上,id 3对instructor表筛选后得到的数据进行Spool操作,并调换instructor和course表进行嵌套循环连接的顺序。
0与4对比
0与5对比,id 0在对teachers表的扫描中采用索引扫描,id 5在对teachers表的扫描中采用全表扫描,并进行根据谓词进行筛选。
0与6对比,在id 8的基础上,对teachers和instructor表的哈希连接、course和teachers_instructor表的哈希连接顺序进行了调换。
0与7对比
0与8对比,id 0对teachers表的扫描采用索引扫描,id 8对teachers表的扫描采用仅索引扫描。
id 7的价值最大,因为id 1、2、3都是在id 7的基础上进行变化得到的。id 1在id 7的基础上,对course表全表扫描后得到的数据进行Spool操作,再进行嵌套循环连接。id 2在id 7的基础上,对teachers表的扫描采用仅索引扫描。id 3在id 7的基础上,对instructor表筛选后得到的数据进行Spool操作,并调换instructor和course表进行嵌套循环连接的顺序。id 7在此起到了承上启下的作用,如果去掉,则显得前面几个案例变化过大而起不到对比学习的作用。
id 2的价值最小,因为根据id 8的例子可知,在当前数据库中,对表采用索引扫描和仅索引扫描所花费时间近乎相同,只在内容上有所区别。而id 2在id 0变化巨大的基础上,再一次的向我们说明这个道理,实属有些多余,故我认为其价值最小。





