
数理逻辑-可信AI笔记
可信AI总结报告
论文来源ACM与IEEE双Fellow、华人女计算机科学家周以真:可信 AI,未来可期 | 雷峰网 (leiphone.com)
一、可信AI的发展历程
人工智能并不是一个新的概念,从1950年的图灵之问开始,到今天产业的蓬勃发展。人工智能系统已经在我们的生活中有着广泛的应用。比如,物体识别可以帮助汽车识别道路;语音识别则有助于个性化语音助手交流。人工智能系统的表现甚至超过了人类,AlphaGo 就是第一个击败世界最强围棋选手的计算机程序。除此之外,OpenAI公司提出了包含1750亿参数的GPT究极进化版模型GPT-3,GPT-3 在许多 NLP 数据集上均具有出色的性能,包括翻译、问答和文本填空任务,这还包括一些需要即时推理或领域适应的任务,例如给一句话中的单词替换成同义词,或执行 3 位数的数学运算。人工智能的前景之广阔,属于人工智能的时代仿佛就此到来。
但是随着人工智能广泛的产业落地,带来的诸多问题也同样不能忽视。AI面临越来越多的可信挑战,人工智能系统可能是不堪一击且不公正的。包含涂鸦的停车标志,良性皮肤病图像上的噪声,这些都有可能成为混淆欺骗分类器的存在。另外一些风险评估、价值评判人工智能系统甚至会出现种族歧视与性别歧视的情况。AI系统的不确定性导致潜在的安全问题,可解释性的缺乏,AI系统如何在使用数据的同时保护用户隐私等,这些种种都成为了对AI更广泛的应用与赋能的限制。
构筑可信AI已成为全球共识,2016年欧盟颁布了《通用数据保护条例(GDPR)》;2017年12月,IEEE提出了《人工智能的伦理设计准则》,之后澳洲、美国、新加坡等都提出了相关的政策、指南或白皮书。国内,何积丰院士于2017年11月香山科学会议上首次提出了“可信人工智能”的概念。2017年12月,工业和信息化部发布了《促进新一代人工智能产业发展三年行动计划》。在此之后,中国的科技公司纷纷提出了可信人工智能发展规划。2019年10月,京东集团就首次在乌镇世界互联网大会上提出京东践行“可信赖AI”的六大维度;京东探索研究院在2021年4月已将“可信人工智能”正式列为主要研究方向之一,并于同年7月联合中国信通院完成撰写、发布国内首本《可信人工智能白皮书》。由上可见,可信AI有着光明的前景。
二、可信AI需要满足的属性
我们可以把可信AI的属性归结到五大方面中:稳定性、可解释性、隐私保护、公平性以及相关的责任划分。以下是文章中给出的几个特性
(1)可靠性:系统做正确的事情吗?
(2)安全性:系统没有危害吗?
(3)保密性:系统是否容易受到攻击?
(4)隐私性:系统是否保护个人的身份和数据?
(5)可用性:当人类需要访问系统时,系统是正常的吗?
(6)实用性:人类可以轻松使用它吗?
(7)准确性:与训练和测试过的数据相比,人工智能系统在新的(不可见的)数据上表现如何?
(8)鲁棒性:系统的结果对输入的变化有多敏感?
(9)公平性:系统的结果是否公正?
(10)问责制:什么人或什么物对系统的结果负责?
(11)透明度:外部观察员是否清楚系统的结果是如何产生的?
(12)可理解性/可解释性:系统的结果是否可以通过人类可以理解和/或对最终用户有意义的解释来证明?
我们希望这些属性能够存在于硬件和软件等计算系统中,以及存在于这些与人类和物理世界交互的系统中。在过去的几十年里,学术界和产业界在可信计算方面取得了巨大的进步。然而,随着技术的进步,人工智能变得越来越复杂,可信计算仍然是一个艰难的梦想。
在一方面,人工智能所需满足的属性复杂难以统一。准确性在机器学习中被认为是一个至关重要的属性,但是其他属性如公平性的满足可能要以牺牲准确性为代价。并且这些特性往往是概念性的或者是模糊的,无法或是难以用统一的标准来衡量。
在另一方面,人工智能训练出的模型是不确定的,即具有概率性质。传统的软件和硬件系统由于其规模和组件之间的交互数量而变得复杂。在大多数情况下,我们可以根据离散逻辑和确定性状态机来定义它们的行为。但对于今天的人工智能系统,尤其是那些使用深度神经网络的系统,给传统的计算机系统增加了一个复杂的维度。这种复杂性是由于它们固有的概率性质。通过概率,人工智能系统对人类行为和物理世界的不确定性进行建模。更多机器学习的最新进展依赖于大数据,这增加了它们的概率性质,因为来自现实世界的数据只是概率空间中的点。因此,可信AI必然会将我们的注意力从传统计算系统的主要确定性本质转向人工智能系统的概率本质。
三、如何信任人工智能——形式验证
当下,机器学习模型大多仍然是“黑盒模型”,即缺乏足够的“可解释性”。何凤翔认为,如果我们不太了解算法背后的机制,就很难预测人工智能的风险从哪里来、风险机制怎么样、尺度如何。“我们不太能管理风险,这样AI算法就很难被用在关键领域中,包括医疗诊断、自动驾驶这种人命关天的行业。所以打破AI技术现今固有的黑盒模式,算法方面的突破是关键。我们需要深刻理解算法,然后在此基础上设计出可以被信赖的算法,才能够更好应对应用风险。”
由于人工智能系统的概率性本质,面对人工智能的种种不确定性,我们很难保证自动驾驶汽车在遇见复杂的路况时能够做出最准确的判断。对于上述的问题,我们该如何设计、执行和部署人工智能系统,使其值得信赖?
在计算系统中建立最终用户信任的一种卓尔有效的方法是形式验证。形式验证的优点是无需逐一测试单个输入值或行为,是一种提供可证保证的方式,从而增加人们对系统将按预期运行的信任。
在传统的形式方法中,我们想要证明一个模型M满足一个属性P。
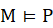
其中,M时要验证的对象,这个对象可以是一个程序,也可以是一个复杂系统的抽象模型。P是用某种离散逻辑表示的正确性属性。为了验证这个M满足P的属性,需要使用形式化的数学逻辑。
特别的,当M是一个并发的、分布式或反应式的系统时,在传统的形式方法中,我们常常为模型M添加上明确的环境 E:
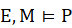
与传统方法相比,我们对验证人工智能系统提出了更多的要求。为了验证ML模型,我们重新解释了M和P,其中M代表机器学习模型。P代表可信的属性,例如安全性、稳健性、隐私性或公平性。我们需要考虑研究机器学习模型固有的概率性质与怎样才能最大化利用数据。
对于M和P固有的概率性质,需要使用概率推理的方法来处理。但是与传统方法不同,模型M本身在语义和结构上就与典型的计算机程序不同,具有内在的概率性。从现实中获取到的输入,通过数学建模成随机过程,并且产生概率性的输出。这种结构导致模型M本身可能并不能被人类所理解,并且人类也很难编写出这种语句。比如,在深度神经网络框架DNN中,产生这个由if-then-else语句组成的复杂结构,并且在对程序分析的过程中开辟了新的研究方向。
人工智能系统的验证将仅限于可以形式化的内容,比如公平性特性,我们可以通过关于相对于实数的损失函数的期望来表示。而对于社会中的透明度和道德感,由于尚未形式化或无法形式化,就需要将模型放置在一个具体的环境中进行分析。
数据对于探寻满足模型的基本属性有着十分重要的价值。数据可以被分为可用数据和不可见数据,我们可以使用可用数据对M进行培训和测试,而不可见数据是M需要在之前没有见过的情况下对其进行操作的数据。即构建出来的模型M可以根据已有的数据对从来没有见过的情况进行判断,并且这个预测在某一程度上是准确的。
这两个关键的区别——M的固有概率性质和数据D的作用——为形式方法社区提供了研究机会,以推进人工智能系统的规范和验证技术。





